Статья:




Решающие деревья и их применение для классификации научных статей
Секция: Физико-математические науки
Выходные данные
Филиппов Р.Р., Торжков И.И. Решающие деревья и их применение для классификации научных статей // Технические и математические науки. Студенческий научный форум: электр. сб. ст. по мат. XLI междунар. студ. науч.-практ. конф. № 6(41). URL: https://nauchforum.ru/archive/SNF_tech/6(41).pdf (дата обращения: 15.11.2024)
Лауреаты определены. Конференция завершена
Эта статья набрала 45 голосов
Мне нравится45
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

XLI Студенческая международная научно-практическая конференция «Технические и математические науки. Студенческий научный форум»
Решающие деревья и их применение для классификации научных статей
Филиппов Роман Русланович
студент, Самарский университет им. С.П. Королёва, РФ, г. Самара
Торжков Илья Игоревич
студент, Самарский университет им. С.П. Королёва, РФ, г. Самара
Додонова Наталья Леонидовна
научный руководитель, канд. физ.- мат. наук, доцент,
Самарский университет им. С.П. Королёва,
РФ, г. Самара
Аннотация. В данной работе была создана программа, решающая задачу классификации текстов с использованием решающих деревьев и проведено её испытание на основе созданной базы данных научных статей.
Ключевые слова: леса решений, решающее дерево, машинное обучение, обучающая выборка, классификация, анализ текста.
УСЛОВИЯ И МЕТОДЫ ИССЛЕДОВАНИЯ
Рассмотрим вопрос: «Для чего нужна программная классификация статей?». Для себя мы определили три основные причины: для экономии времени подбора необходимых статей пользователем, для создания автоматических таргетированных ссылках на сайтах и для автоматической классификации по единому шаблону при вносе статьи в базу данных.
В ходе работы были проведены исследования по поводу создания собственной консольной программы на системах с различными операционными системами для обеспечения кроссплатформенности, с помощью языка программирования Python версии 3.6.9, библиотек PDFMiner и Numpy.
Во время исследования были использованы такие методы, как сортировка слов, входящих в статью, по частоте их появления, исключение слов с небольшим (менее четырёх) количеством букв с целью избавления от не несущих смысловой нагрузке конструкций, построение решающего бинарного дерева заданной высоты, выбор наиболее эффективных деревьев и формирование на их основе леса решений, проход по лесу с поиском наиболее подходящего решающего дерева.
При составлении базы данных были использованы статьи из репозитория Самарского Университета. Статьи для тренировки были выбраны по категориям «Авиационные двигатели», «Английский язык», «Информатика» и «Обществознание» в количестве 48 штук. Также мы взяли 12 статей из этих же разделов для проверки работы алгоритма на работоспособность.
Разработанная программа состоит из трех частей. Первая часть обрабатывает статьи в формате PDF, сохраняет 100 наиболее частых слов из статьи, длина которых не менее четырех символов, и записывает их в файлы с расширением .txt, из которых формируется итоговая база данных. Вторая часть создаёт лес решений на основе базы данных. Третья часть пропускает через созданный лес статьи в PDF формате, которые подлежат классификации.
Алгоритм построения решающего дерева представлен ниже. Функция, создающая дерево, принимает на вход необходимую высоту создаваемого дерева и размещение, которое задаёт последовательность номеров условий, выбираемых для каждого уровня бинарного решающего дерева. Применяя к каждой статье из тренировочной выборки поочерёдно все возможные условия, находится подмножество статей тренировочного набора, применение к которым данного варианта условий позволяет определить максимальное число статей из тренировочного набора. Через дерево с проверяемым на данном шаге условием пропускаются все статьи из тренировочного набора; в листьях подсчитывается количество дошедших до данного листа статей каждого типа. Для каждого листа считается вероятность попадания в него статьи каждого типа из тренировочного набора. По найденным вероятностям считается внутренняя энтропия. Данная энтропия считается как равномерность распределения вариантов внутри одного листа. Лучшим является вариант отсутствия разделения на варианты, то есть значение энтропии, равное нулю. После этого ведется подсчет того, сколько вариантов попало в каждый лист, и на их основе ведется подсчет вероятности попадания в каждый отдельный лист. Данный параметр используется во внешней энтропии, где рассматривается равномерность распределения вариантов по листьям. Наилучший результат для этого показателя – наибольшее значение, что означает, что распределение среди всех вариантов деревьев наиболее равномерное. В качестве ответа выбирается дерево, имеющее наилучший показатель внешней энтропии. Если таких несколько, то выбирается то, у которого лучший показатель внутренней энтропии.
РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
В результате исследования была выявлена зависимость качества получаемого результата от высоты дерева и используемых условий. В качестве условий используются наборы слов с наивысшей частотностью и отдельные слова из текстов, подбираемые автоматически в ходе работы программы, обучающей модель.
На каждой высоте выбирались лучшие деревья в количестве, равном мощности множества предикатов, и для них на следующей высоте проверялись все возможные предикаты. Затем из полученных деревьев опять выбиралось то же количество лучших. Это позволило точно определять все статьи из тестовой выборки. На контрольной выборке была получена точность определения темы статьи 91,7% для лесов с максимальной высотой 5. Результаты, полученные при проведении данного исследования, представлены на рис. 1 и рис. 2.
Вне зависимости от полученных результатов есть возможность улучшения разработанной программы. Есть три направления, развитие которых позволит программе стать более эффективной. Первое из них – это создание более обширной базы данных на основе тысяч статей при доведении леса решений до высоты, при которой вероятность определения статьи из тренировочной выборки будет максимальной. Второе – углубление и расширение классификации статей, увеличение количества тем статей и введение внутри них классификации по подтемам. Третье – представление ключевых слов в виде вектора признаков и расчёт расстояния между ним и искомым словом в многомерном пространстве признаков.
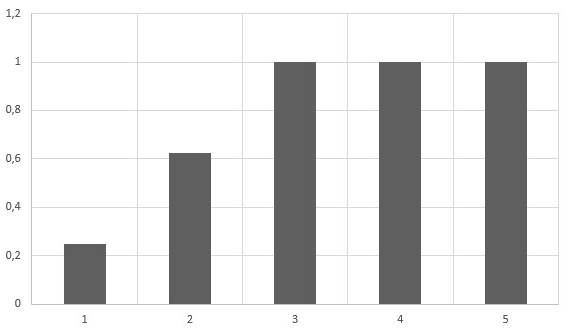
Рисунок 1. Зависимость вероятности определения статьи из контрольной выборки от максимальной высоты леса

Рисунок 2. Зависимость вероятности определения статьи из тренировочной выборки от максимальной высоты леса
Данное направление может позволить уменьшить максимальную высоту леса решений и позволит работать с ключевыми словами с учётом их смысловой нагрузки. Рассмотрим этот вариант улучшения на примере. Слова «авиация» и «самолёт» в многомерном пространстве стоят близко друг к другу, что будет показывать то, что они близки по смыслу и, вероятно, будут чаще встречаться в статьях с похожими темами. В свою очередь слово «дерево» будет находится далеко от них, что даст понятие о том, что оно не пересекается с предыдущими словами не только по смыслу, но и по предметной отрасли.
ЗАКЛЮЧЕНИЕ
В результате изложенных выше исследований была разработана консольная программа, позволяющая определять тему научной статьи с вероятностью, близкой единице, что может быть использовано для избавления от необходимости классификации человеком и возможности автономной классификации статей без влияния человеческого фактора. При дальнейшей доработке разработанная программа способна сэкономить время при поиске статей по определенной теме. Также перспективным направлением разработки данной программы может стать создание автономных таргетированных ссылок на электронных ресурсах, пересылающих на статьи похожего содержания.
Список литературы:
1. Андрей Себрант (Яндекс) — Бизнес в Эпоху Искусственного Интеллекта. URL: https://www.youtube.com/watch?v=K1xOb5ZfOXk&feature=youtu.be&ab_channel=amoCRM%5BRU%5DD (дата обращения: 21.12.2020)
2. Гошин Е.В. Теория информации и кодирования [Электронный ресурс]. Доступ из репозитория Самарского Университета.
3. Кафтанников И. Л., Парасич А. В. Особенности применения деревьев решений в задачах классификации. URL: https://cyberleninka.ru/article/n/osobennosti-primeneniya-dereviev-resheniy-v-zadachah-klassifikatsii (дата обращения: 21.12.2020)
4. CatBoost - градиентный бустинг от Яндекса. URL: https://www.youtube.com/watch?v=UYDwhuyWYSo&feature=youtu.be&ab_channel=ComputerScienceCenter (дата обращения: 21.12.2020)
