МОДЕРНИЗАЦИЯ ОБНАРУЖЕНИЯ ИНСАЙДЕРСКОЙ УГРОЗЫ С ПРИМЕНЕНИЕМ ИМИТАЦИОННОГО МОДЕЛИРОВАНИЯ ПОЛЬЗОВАТЕЛЬСКОЙ АКТИВНОСТИ В ИНФОРМАЦИОННОЙ СИСТЕМЕ
Конференция: LVII Международная научно-практическая конференция «Научный форум: технические и физико-математические науки»
Секция: Информатика, вычислительная техника и управление

LVII Международная научно-практическая конференция «Научный форум: технические и физико-математические науки»

МОДЕРНИЗАЦИЯ ОБНАРУЖЕНИЯ ИНСАЙДЕРСКОЙ УГРОЗЫ С ПРИМЕНЕНИЕМ ИМИТАЦИОННОГО МОДЕЛИРОВАНИЯ ПОЛЬЗОВАТЕЛЬСКОЙ АКТИВНОСТИ В ИНФОРМАЦИОННОЙ СИСТЕМЕ
Аннотация. Инсайдерские угрозы - это злонамеренные действия, мошенничество и саботаж в лице пользователей, которые прошли аутентификацию в системе легальным путём. Такие действия, как правило, совершаются в отношении информации об интеллектуальной собственности или безопасности. Несмотря на то, то количество внутренних угроз намного меньше, чем атак со стороны внешних хакеров, инсайдеры могут нанести значительный ущерб. Поскольку инсайдеры знакомы с организационной системой, очень сложно определить их вредное поведение. Консервативные пути выявления внутренних угроз направлены на длительное и трудоёмкое поисковое действие, поэтому они не являются достаточно эффективными и не всегда безошибочны. В данной статье предлагается методика изобличения инсайдеров, работающая за счёт алгоритмов вычисления аномалий и моделирования наиболее вероятного поведения пользователей в охраняемом информационном пространстве. Анализируя системные логи из источников данных о действиях пользователя можно запротоколировать сведения об их действиях и составить картину нормального поведения. Такие сведения можно черпать, к примеру, из содержимого электронной почты, журналов событий на рабочих станциях пользователей, временных промежутках активности пользователей и т. д. После этого, на основании полученных данный создаётся алгоритм, выявляющий подозрительное и некорректное поведение пользователя, обращение им к информации, являющейся избыточной для выполнения его служебных обязанностей и выходящей за рамки его компетенций. Тем самым алгоритм подмечает вероятное направление реализации в последующем вредоносных действий. Таким образом, возникает иной способ изобличения инсайдера, основная его положительная черта в сравнении с другими подходами в независимости от свойств случайных процессов, характеризующих работу пользователя. Кроме того, данный подход снижает вероятности ошибок первого и второго рода, то есть на выходе получится куда меньшее количество как ложных срабатываний, так и упущенных, но реально присутствующих угроз безопасности. Для исключения ложных срабатываний предложенный метод в том числе опирается на теорию запретов, в рамках которой задана вероятностная величина, описывающая действия пользователя, не содержащих злого умысла. За счёт этого обосновывается точность построенного алгоритма обнаружения реальных внутренних угроз в большом массиве пользователей. В методе создаётся новое программное средство, моделирующее деятельность честных пользователей и инсайдеров в системе в виде имитации. Такое ПО помогает оценить границы реальной применимости консервативных методов математической статистики в новом подходе, основанном на имитационном моделировании. Неразрывно с математической статистикой в исследовании также применяются все применимые в данной ситуации методы теории вероятностей и теории множеств. При изучении теоретической части исследуемой области был проведен научный анализ имеющихся результатов в применении теории запретов и современных методик распознавания инсайдеров. При подтверждении практической эффективности предлагаемого метода произведено имитационное моделирование. Создаваемый подход даёт возможность проводить анализ инцидентов информационной безопасности, связанных с любыми вероятностными событиями, как несанкционированные действиями пользователей, так и любые другие. Этот метод может применяться и для улучшения ныне уже существующих систем обнаружения внутренних нарушителей, и в качестве нового независимого метода обнаружения несанкционированного сбора информации работниками.
Ключевые слова: инсайдер; моделирование поведения; внутренний нарушитель; теория статистики; информационная безопасность; инсайдерская угроза; вероятностная модель; алгоритм обнаружения аномалий.
1. Введение
Инсайдерская угроза – это угроза безопасности, определяемая тем, что в числе доверенных лиц внутри охраняемой сети присутствует злоумышленник [1]. Несмотря на то, что угрозы внутреннего характера случаются не часто, размер их ущерба превышает потери от внешних атак [2,3]. Инсайдеры располагают всей необходимой информацией о компьютерной сети своей организации и имеют легальный доступ ко всем операционным процессам. Иногда не удаётся своевременно определить, когда их действия носят злонамеренный характер [4]. Был создан ряд системных технологий защиты от вторжения извне, таких как количественная оценка интернет-протокола подключения (IP) и разновидности атаки [5]. Всё это в целом указывает на то, что в направлении информационной безопасности приоритет отдаётся защите от внешних нарушителей, а поиск внутренних угроз получает недостаточно внимания и ресурсов [6].
Имеется три ключевых стратегии исследования для выявления внутренних угроз. Первая стратегия при построении системы обнаружения опирается на правила и сценарии [7,8]. Для этого экспертной группой создаются сценарии злонамеренных действий внутренних нарушителей. В последующем поведение всех пользователей фиксируется в форме журнала действий и регулярно проверяется на предмет соответствия ранее описанным сценариям. Такой способ выявления инсайдеров имеет существенный недостаток, состоящий в необходимости непрерывной доработки и написании новых сценариев экспертными группами в данной отрасли, иначе, при их устаревании, сразу возникает риск обойти их [9]. Таким образом, метод, основанный на сценариях, не обеспечивает должного уровня защищенности от внутренних угроз [7,10,11]. Вторая стратегия основана на создании сетевого интерфейса для обнаружения подозрительного или нежелательного поведения посредством мониторинга изменений в графической структуре [12]. Помимо того, что этот метод определяет не только аналитическую ценность самих сведений, но он так же устанавливает взаимосвязь между ними. Взаимосвязи представлены в виде рёбер, связывающих узлы графика. Свойства графиков можно подвергнуть аналитической проверке для установления связей между конкретными узлами и внутренними угрозами. Таким образом, патологические действия позволяют определить, когда модификации, добавление или стирание достигают базовой структуры графика данных. Третья стратегия основана на создании статистической модели обучения, учитывающей сведения о прошлом для прогнозирования потенциально опасного поведения [14]. Машинное обучение – это методика, при которой машина обучается алгоритму оптимизации критериев производительности в соответствии с данными обучения для исполнения необходимых задач [15]. Внутреннее обнаружение угроз в машинном обучении предназначено для создания механизма автоматического вычисления пользователей, совершающих нормальные действия, из общего числа работников, не имея никаких заранее прописанных правил. Концепция машинного обучения опирается на принцип постоянного обучения и доработки алгоритмов с использованием больших данных. Такой подход обеспечивает более надежное выявление внутренних нарушителей в сравнении с составленными экспертами вручную сценариями. Методология машинного обучения способна формировать возможные сценарии внутреннего нарушителя, вызывающие несанкционированные действия, анализируя высокоуровневые статистические модели. В этих целях определяются переменные, которые представляют собой различные действия внутреннего нарушителя как, например, электронные письма, файлы и подключение, в последующем используются статистические показатели и всевозможные алгоритмы машинного обучения для выбора самого подходящего сценария поведения. Например, можно определить инсайдера, анализируя сходство поведения между ролью Группы, в которую пользователь фактически входит, и другой ролью Группы, к которой он не относится, полагая, что пользователи в одних и тех же группах ролей обладают аналогичными моделями поведения. Так как поведение пользователя можно получить из разнообразных источников информации, например, из системных журналов, отправленной и полученной электронной почты, из вложений электронной почты, в таком случае основным моментом в создании эффективной модели обнаружения инсайдеров является выявление полезных функций для всяческих типов данных и преобразование неструктурированных исходных данных в упорядоченную последовательность.
Для устранения минусов всех трёх вышеизложенных подходов к идентификации внутренних нарушителей предлагается новый подход выявления инсайдеров, основанный на имитационном моделировании поведения пользователя. На старте, в ходе моделирования действий пользователя во внимание берутся три типа сведений. Во-первых, перечень журналов активности физического лица, зарегистрированных в системе. В случае, если системные журналы включают сведения о том, что пользователь подключает к машине съёмный USB-накопитель, то суммарное количество подключений каждый день можно найти в качестве переменной. Во-вторых, изучается создаваемый пользователем контент, такой как, к примеру, содержимое писем электронной почты. В-третьих, выстраивается сеть общения с пользователями на основе электронной почты, обмена файлами. После этого для узла вычисляются сводные статистические данные, в дальнейшем они помогают определении поведенческих признаков. При построении модели обнаружения угроз учитываются извлеченные и накопленные на основе трех категорий данные для изучения характеристик обычной деятельности.
2. Набор данных и моделирование поведения пользователей
Поведение пользователя хранится в базе данных в виде соответствующих таблиц: авторизация в системе, использование USB-носителей, скачанные файлы и т. д. Для мультифакторного анализа поведения пользователей следует систематизировать накопленные данные, поэтому информацию о поведении необходимо располагать в хронологическом порядке, а также упорядочивать на регулярной основе. Рассматривая фрагментированную активность пользователя на ежедневной основе и складывая её, мы получаем входную переменную модели выявления угроз, описывающую интенсивность деятельности. Для нахождения входных переменных для выявления угроз, применяются входные сведения подобные тем, что представлены таблицах 1 и 2. Поэтому, сводная информация о поведении за конкретный день, собранная для каждого пользователя системы, сравнивается с нормальным поведением. Модель, представленная в таблицах, и значения аномалий – это лишь малая часть, характеризующая имитацию инсайдерского поведения, в которой его можно идентифицировать. Чаще всего нестандартное поведение (почти 90%) фиксируется со стороны трёх ролевых лиц: "Продавец", "ИТ-администратор", "Инженер-электрик". Поэтому для них существует больший запас для записи приемлемого числа аномалий. В ином случае, когда аномальные данные поступают от разработчиков или программистов. В этом случае система сразу же сосредотачивается на поиске возможных внутренних угроз.
Таблица 1.
Количество допустимых аномальных записей в соответствии с ролью
|
Роль |
Количество допустимых аномальных записей |
|
Продавец |
32 |
|
ИТ-администратор |
23 |
|
Инженер-электрик |
10 |
|
Компьютерный программист |
3 |
|
Менеджер |
2 |
|
Директор |
1 |
|
Рабочий производственной линии |
1 |
|
Разработчик ПО |
1 |
|
Всего |
73 |
Таблица 2.
Частота записей трех ролей
|
Инженер-электрик |
ИТ-администратор |
Продавец |
|||
|
Нормальная |
Аномальная |
Нормальная |
Аномальная |
Нормальная |
Аномальная |
|
141,199 |
10 |
34,244 |
23 |
125,524 |
32 |
В табл. 3 приведены данные для выявления внутреннего нарушителя на основе анализа содержимого электронной почты. Столбцы “Тема 1” - “Тема 50” показывают вероятности, назначенные по 50 темам на индивидуальное электронное письмо и используются в качестве входной переменной модели обнаружения аномалий. Сумма вероятностей 50 тем всегда равна 1. “Идентификатор” – это уникальный номер строки для разных наблюдений. “Цель” – это переменная, указывающая на то, является ли электронное письмо аномальным (1) или нормальным (0). В табл. 4 показано количество аномальных и нормальных электронных писем для каждой из трёх ролей. Предполагается, что распределение тем почты для каждой роли осуществляется подобным образом. Так, если распределение определенного электронного письма значительно разнится с другими электронными письмами, то это является основанием подозревать присутствие вредоносных действий.
Таблица 3.
Количественные примеры содержимого электронной почты
|
Идентификатор |
Тема 1 |
Тема 2 |
… |
Тема 50 |
Цель |
|
(I1O2-B4EB49RW-7379WSQW) |
0.008 |
0.012 |
… |
0.154 |
1 |
|
(L7E7-V4UX89RR-3036ZDHU) |
0.021 |
0.008 |
… |
0.125 |
1 |
|
(S8C2-Q8YX87DJ-0516SIWZ) |
0.014 |
0.006 |
… |
0.145 |
0 |
|
(A1V9-O5BL46SW-1708NAEC) |
0.352 |
0.014 |
… |
0.086 |
0 |
|
(N6R0-M2EI82DM-5583LSUM) |
0.412 |
0.058 |
… |
0.285 |
0 |
|
(O2N1-C4ZZ85NQ-8332GEGR) |
0.085 |
0.421 |
… |
0.001 |
0 |
Таблица 4.
Нормальное и аномальное количество электронных писем для трех ролей
|
Инженер-электрик |
ИТ-администратор |
Продавец |
|||
|
Нормальное |
Аномальное |
Нормальное |
Аномальное |
Нормальное |
Аномальное |
|
644,252 |
40 |
170,765 |
15 |
694,050 |
13 |
Так как сведения об отправителе/получателе можно также получить из записей журнала электронной почты, в дальнейшем можно на регулярной основе строить граф в виде связей пользователей по электронной почте и извлекать количественные характеристики в качестве третьего источника анализа активности пользователей для выявления инсайдерской угрозы.
3. Обнаружение инсайдерской угрозы
На рисунке 1 отображена общая структура метода обнаружения внутренних угроз. На стадии моделирования поведение пользователя, хранящееся в системе каждого журнала, преобразуется в три типа наборов данных: сводка повседневной деятельности, содержимое электронной почты и электронная почта в качестве сети связи. На стадии обнаружения аномалий используются алгоритмы классификации одного класса на основе трёх наборов данных. Как только новая запись становится доступной, она помещается в одну из этих трех частей модели, чтобы предсказать возможные вредоносные результаты.
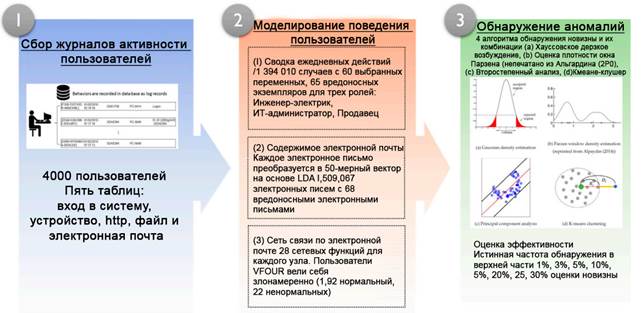
Рисунок. 1. Система обнаружения внутренних угроз
Для домена обнаружения внутренних угроз очень часто доступно очень большое количество случаев нормальной активности пользователя, тогда как ненормальных случаев доступно лишь несколько или совсем нет. В этом случае традиционные алгоритмы бинарной классификации не могут быть обучены из-за отсутствия аномальных классов [19]. В качестве альтернативы, в несбалансированных средах данных в отличие от бинарной классификации, классификация с одним классом использует только данные обычного класса для изучения их общих характеристик, не полагаясь на данные аномального класса [20]. Как только модель классификации одного класса обучена, она предсказывает вероятность того, что вновь заданный экземпляр будет обычным экземпляром класса. В этой статье используется анализ основных компонентов (PCA), оценка плотности Гаусса (Gauss), оценка плотности окна Парзена (Parzen) и кластеризация K-средних (KMC) в качестве алгоритмов одноклассовой классификации для выявления внутренних угроз, как показано на рисунке 2.
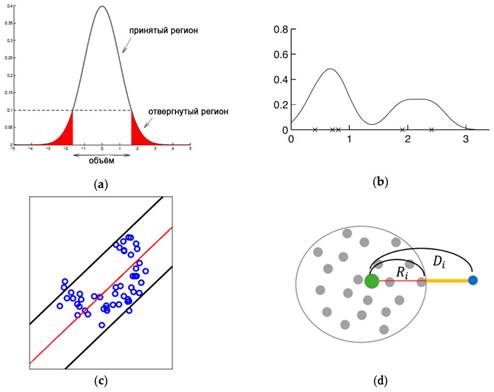
Рисунок 2. Четыре алгоритма обнаружения аномалий, используемые в этой статье:
(a) оценка плотности по Гауссу, (b) оценка плотности окна Парзена, (c) анализ главных компонентов (PCA) и (d) кластеризация K-средних (KMC).
Для внутреннего обнаружения угроз, как правило, поддерживается очень большое количество обычной деятельности пользователей, однако для аномальных случаев это число крайне мало. В случае традиционных алгоритмов бинарной классификации они не могут быть изучены из-за отсутствия аномальных классов [17]. Как альтернатива, классификация по несбалансированной информации, в отличие от двоичной классификации, использует для изучения данные только от общего класса, не учитывая аномальный класс [16]. После того, как распределенная модель обучается классом, она предугадывает вероятность того, что все новые примеры. В этой статье используется оценка плотности по Гауссу (Gauss), уплотнение загрузочных окон (Parzen), анализ основных компонентов (PCA) и кластер k-среднего (KMC) используется в качестве единого алгоритма классификации для выявления внутренних угроз, как видно на рисунке 2.
Помимо индивидуального выявления аномалий алгоритмов, нас интересует и комбинация этих алгоритмов. Даже при изучении одних и тех же данных методология создания оптимальной модели для каждого алгоритма различна, поэтому нет единого алгоритма, который лучше во всех ситуациях [16]. Итак, мы рассмотрели все возможные комбинации четырех отдельных детекторов аномалий с целью определить оптимальную комбинацию набора данных.
4. Результаты
Обычно алгоритм вычисления аномалий обучается только на основе обычных данных в ситуациях, когда большая часть случаев находится в нормальном классе, а только несколько экземпляров в ненормальном классе. При таком раскладе проблематично установить порог обнаружения. Качественные свойства обнаружителей аномалий оцениваются в следующем порядке. Сначала информация разбивается на набор данных, содержащий 90% выбранных произвольно нормальных экземпляров, и ещё на 10% тестовых данных, который содержит остаточные нормальные экземпляры, а также полный перечень ненормальных экземпляров. Затем алгоритм обнаружения обучается только на базе обучающих данных. В итоге вычисляется истинная вероятность выявления в соответствии с семью значениями порога (1%, 5%, 10%, 15%, 20%, 25% и 30%) по уравнению:
 (1)
(1)
Чтобы получить статистически допустимые результаты, данный алгоритм воспроизводится 30 раз. Для каждого алгоритма обнаружения аномалий средний истинный коэффициент обнаружения в верхнем X% применяется в качестве показателя действенности выявления внутреннего нарушителя.
В таблицах 5-7 показана эффективность охвата внутренних нарушителей лучшей из выбранных комбинаций (например, «Parsen + PCA»), на основе данных о ежедневной активности для трех ролей: «ИТ-администратор», «Продавец» и «Инженер-электрик». Как объяснялось ранее, мы протестировали все комбинации нескольких моделей «Parsen + PCA», так что это привело к лучшей совместимости в 10 случаях из 21, за которыми последовал «Gauss + Parsen + PCA» (5 случаев). Так в числе первых 1% оценок аномалий с наивысшим рейтингом, предугаданных Gauss для «Инженер-электрик», с легкостью выявляется половина вредоносных действий, что уже в 50 больше, чем способна распознать случайная модель, которая в конечном итоге обнаруживает лишь 1% ненормального поведения.
Таблица 5.
Истинная вероятность обнаружения аномалий для каждого алгоритма на основе анализа повседневных действий, сводка для «Инженер-электрик» (наилучший результат – жирным шрифтом)
|
Ранг аномалии |
Gauss |
Parsen |
PCA |
КМС (К = 3) |
КМС (К = 5) |
КМС (К = 10) |
Parsen + PCA |
|
1% |
0.5000 |
0.4000 |
0.4933 |
0.5233 |
0.5333 |
0.5367 |
0.4833 |
|
5% |
0.6000 |
0.5000 |
0.6667 |
0.6400 |
0.6300 |
0.6333 |
0.7633 |
|
10% |
0.6167 |
0.7933 |
0.7467 |
0.7033 |
0.6467 |
0.6933 |
0.7933 |
|
15% |
0.7000 |
0.9000 |
0.7800 |
0.7167 |
0.6767 |
0.7333 |
0.8000 |
|
20% |
0.7000 |
0.9000 |
0.7900 |
0.7500 |
0.6967 |
0.7600 |
0.8167 |
|
25% |
0.7000 |
0.9000 |
0.8000 |
0.7767 |
0.7433 |
0.7767 |
0.8233 |
|
30% |
0.7000 |
0.9000 |
0.8033 |
0.7677 |
0.7700 |
0.7933 |
0.8500 |
Таблица 6.
Истинная вероятность обнаружения аномалий для каждого алгоритма на основе анализа повседневных действий, сводка для «ИТ-администратор» (наилучший результат – жирным шрифтом)
|
Ранг аномалии |
Gauss |
Parsen |
PCA |
КМС (К = 3) |
КМС (К = 5) |
КМС (К = 10) |
Parsen + PCA |
|
1% |
0.0435 |
0.0478 |
0.0739 |
0.0580 |
0.0521 |
0.0522 |
0.0971 |
|
5% |
0.0435 |
0.1739 |
0.2130 |
0.0841 |
0.0739 |
0.0768 |
0.2174 |
|
10% |
0.0435 |
0.3015 |
0.2304 |
0.1246 |
0.1087 |
0.1174 |
0.2580 |
|
15% |
0.0971 |
0.3043 |
0.2884 |
0.1391 |
0.1275 |
0.1362 |
0.2913 |
|
20% |
0.1594 |
0.3043 |
0.3348 |
0.2333 |
0.2000 |
0.2043 |
0.3246 |
|
25% |
0.1739 |
0.3043 |
0.3681 |
0.3029 |
0.2681 |
0.2797 |
0.3551 |
|
30% |
0.2609 |
0.3043 |
0.4087 |
0.3493 |
0.3304 |
0.3406 |
0.3928 |
Для роли «Инженер-электрик», где 1% наиболее вероятного аномального поведения контролируется ежедневно, система способна обнаружить не более 53,66% фактических конфиденциальных данных. Эти показатели возрастают до 76,33%, 79,33% и 90%, при этом процент наблюдаемых аномального поведения возрастает до 5%, 10% и 15% соответственно. Для роли "ИТ-администратор" выявление не настолько вероятно, как у «Инженер-электрик», но тем не менее ощутимо лучше, чем случайная модель. Увеличение истинной вероятности выявления в сравнении со случайным предположением – 9,71%, отсечка 1% или 21,74%.
Таблица 7.
Истинная вероятность обнаружения аномалий для каждого алгоритма обнаружения на основе анализа повседневных действий, сводка для «Продавец» (наилучший результат – жирным шрифтом)
|
Ранг аномалии |
Gauss |
Parsen |
PCA |
КМС (К = 3) |
КМС (К = 5) |
КМС (К = 10) |
Parsen + PCA |
|
1% |
0.0093 |
0.1177 |
0.0781 |
0.0375 |
0.0396 |
0.0281 |
0.1021 |
|
5% |
0.0313 |
0.3217 |
0.3375 |
0.1083 |
0.0843 |
0.0802 |
0.3406 |
|
10% |
0.0313 |
0.5677 |
0.5458 |
0.1396 |
0.1125 |
0.1135 |
0.6156 |
|
15% |
0.6563 |
0.5844 |
0.6625 |
0.2604 |
0.1969 |
0.2115 |
0.7958 |
|
20% |
0.6563 |
0.7781 |
0.7177 |
0.2938 |
0.2427 |
0.2416 |
0.8646 |
|
25% |
0.6563 |
0.8396 |
0.7677 |
0.3240 |
0.2854 |
0.2802 |
0.9041 |
|
30% |
0.6563 |
0.8719 |
0.8042 |
0.3927 |
0.3260 |
0.3219 |
0.9479 |
Среди всех алгоритмов Parsen показал самые высокие показатели обнаружения в 8 случаях из 21. Обратите также внимание на то, что комбинация «Parsen + PCA» в ряде случаев обеспечивает высочайшую результативность обнаружения.
5. Заключение
В этой статье предложен метод обнаружения внутренних угроз на основе поведения пользователя, с применением алгоритмов моделирования и обнаружения аномалий. При моделировании поведения пользователей разнородное поведение преобразуется в структурированный набор данных (день пользователя, содержимое электронной почты, неделя пользователя), где каждый столбец связан с входными переменными для моделей обнаружения аномалий. Построено два набора данных, а именно набор сводных данных об активности на основе журналов активности пользователей и набор данных содержимого электронной почты на основе темы моделирования. На основе этих наборов данных продемонстрирована система обнаружения внутренних угроз с использованием имитационного моделирования и алгоритмов обнаружения аномалий для имитации реального поведения инсайдеров, которые ведут себя потенциально злонамеренно. Экспериментальные результаты показывают, что предложенная структура может достаточно хорошо работать для обнаружения инсайдеров. На основе ежедневной активности обнаружение аномалий обеспечило 53,67 % вероятность обнаружения инсайдера, отслеживая при этом только 1 % подозрительных действий. Когда охват подозрительных действий был расширен до 30%, то уже более 90% фактического аномального поведения были обнаружены для двух ролей из трех оцениваемых. Хотя предложенная схема была проверена эмпирически, в ней есть некоторые ограничения. Предложенная модель обнаружения внутренних угроз работает на основе конкретных единиц времени, например, сутки. Другими словами, этот подход может обнаруживать злонамеренное поведение на основе продолжительного времени, но не может обнаружить их в режиме реального времени. Следовательно, возможно, стоит разработать модель обнаружения внутренних угроз на основе последовательности, которая способна обрабатывать данные онлайн-потока.
