Статья:




МОДИФИКАЦИЯ АЛГОРИТМОВ ВЫДЕЛЕНИЯ СОЦИАЛЬНЫХ СООБЩЕСТВ НА ОСНОВЕ ИНФОРМАЦИОННОГО СОДЕРЖАНИЯ
Секция: 3. Информационные технологии
Выходные данные
Козлович И.С. МОДИФИКАЦИЯ АЛГОРИТМОВ ВЫДЕЛЕНИЯ СОЦИАЛЬНЫХ СООБЩЕСТВ НА ОСНОВЕ ИНФОРМАЦИОННОГО СОДЕРЖАНИЯ // Молодежный научный форум: Технические и математические науки: электр. сб. ст. по мат. XXXIV междунар. студ. науч.-практ. конф. № 5(34). URL: https://nauchforum.ru/archive/MNF_tech/5(34).pdf (дата обращения: 28.12.2024)
Лауреаты определены. Конференция завершена
Эта статья набрала 30 голосов
Мне нравится31
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников

XXXIV Студенческая международная заочная научно-практическая конференция «Молодежный научный форум: технические и математические науки»
МОДИФИКАЦИЯ АЛГОРИТМОВ ВЫДЕЛЕНИЯ СОЦИАЛЬНЫХ СООБЩЕСТВ НА ОСНОВЕ ИНФОРМАЦИОННОГО СОДЕРЖАНИЯ
Козлович Ирина Сергеевна
магистрант 2 курса группы 14 ФИИТ(м)ИС Оренбургского государственного университета, кафедра геометрии и компьютерных наук, РФ, г. Оренбург
Болодурина Ирина Павловна
научный руководитель, д-р техн. наук, проф., заведующая кафедрой прикладной математики Оренбургского государственного
университета,
РФ, г. Оренбург
В настоящее время социальные сети становятся все более популярными. При этом увеличивается не только число пользователей в одной социальной сети, но и увеличивается число самих социальных сетей. В связи с этим возникает огромное множество актуальных и интересных для исследования задач, связанных со структурированием, обработкой и анализом информации, содержащейся в социальных сетях. Решение одной из таких задач, а именно задачи метрической кластеризации выделения сообществ в социальных сетях, – предмет данной статьи.
Анализ социальных сетей – это направление, которое занимается описанием и анализом социальных сетей посредством различных методов, в том числе с помощью теории графов. Одной из основных задач анализа социальных сетей является определение групповых структур сетей (сообществ). Сообщество, или кластер – это набор вершин, относительно сильно связанных друг с другом, и, возможно, обладающих общими свойствами или играющих схожие роли в сети. Знания о структуре сообществ незаменимы для предсказания связей и атрибутов пользователей, расчёта близости пользователей в социальном графе, оптимизации потоков данных в социальной сети, некоторых аналитических приложений и т.д. Существует множество критериев для графа, которые показывают некоторую его качественную характеристику. Широко используемым критерием для обнаружения сообщества является модулярность. Модулярность - это скалярная величина из отрезка [−1, 1], которая количественно описывает неформальное определение структуры сообществ:
 ,
,
где: m - количество связей, ![]() - матрица смежности графа, ki - степень вершины
- матрица смежности графа, ki - степень вершины
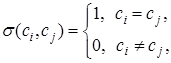
ci - номер класса, к которому принадлежит вершина i.
Задача поиска выделения сообществ в графе сводится к поиску таких сi, которые максимизируют значение модулярности. Достоинства модулярности заключаются в том, что она достаточно просто интерпретируется. Ее значение равно разности между долей ребер внутри сообщества и ожидаемой доли связей, если бы ребра были размещены случайно. Модулярность возможно эффективно пересчитывать при небольших изменениях в кластерах.
Обработка социальных данных требует также разработки соответствующих алгоритмических и инфраструктурных решений, позволяющих учитывать их размерность. К примеру, граф социальной сети Facebook на сегодняшний день содержит более 1 миллиарда пользовательских аккаунтов и более 100 миллиардов связей между ними. Каждый день пользователи добавляют более 200 миллионов фотографий и оставляют более 2 миллиардов комментариев к различным объектам сети. На сегодняшний день большинство существующих алгоритмов, позволяющих эффективно решать актуальные задачи, не способны обрабатывать данные подобной размерности за приемлемое время [2,5–10]. В связи с этим, возникает потребность в новых решениях, позволяющих осуществлять распределённую обработку и хранение данных без существенной потери качества результатов.
В данной статье рассмотрим метод, с помощью которого можно эффективно выделять сообщества в сети, базируясь на модификации алгоритмов для нахождения сообществ [3]. Общую схему работы алгоритма выделения сообществ можно представить следующим образом.
Изначально каждая вершина считается отдельным сообществом. Вычисляется целевая функция L(M)
 , (1)
, (1)
где: 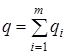 - вероятность перехода между сообществами на каждом шаге случайного блуждания, qi - вероятность покинуть сообщество i, pα - вероятность посетить вершину α,
- вероятность перехода между сообществами на каждом шаге случайного блуждания, qi - вероятность покинуть сообщество i, pα - вероятность посетить вершину α, ![]() - вероятность остаться в сообществе i. Энтропию переходов между сообществами, определяемую как нижняя граница средней длины кодового слова для именования сообществ, представим в виде
- вероятность остаться в сообществе i. Энтропию переходов между сообществами, определяемую как нижняя граница средней длины кодового слова для именования сообществ, представим в виде
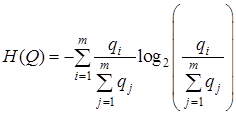 , (2)
, (2)
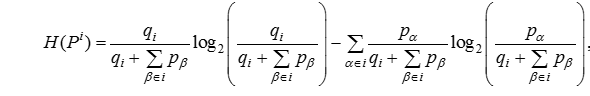 (3)
(3)
![]() - энтропия перемещения внутри сообщества i, нижняя граница средней длины кодового слова для именования вершин в сообществе i. Тогда более детальное описание метрики L(M) можно представить в виде
- энтропия перемещения внутри сообщества i, нижняя граница средней длины кодового слова для именования вершин в сообществе i. Тогда более детальное описание метрики L(M) можно представить в виде
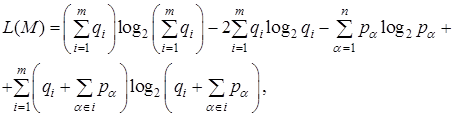 (4)
(4)
где: 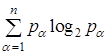 не зависит от разбиения сети на сообщества. Поэтому, при оптимизации разбиения сети, необходимо учитывать все изменения:
не зависит от разбиения сети на сообщества. Поэтому, при оптимизации разбиения сети, необходимо учитывать все изменения: ![]() — вероятность, с которой случайное блуждание входит и выходит из сообществ, и
— вероятность, с которой случайное блуждание входит и выходит из сообществ, и ![]() — долю времени, которую случайное блуждание проводит в каждом из
— долю времени, которую случайное блуждание проводит в каждом из
сообществ.
Далее случайное блуждание формирует последовательность вершин. С учётом частоты встречаемости вершин в полученной последовательности выбираются подмножества вершин, которые объединяются в сообщества. Для заданного разбиения вычисляется метрика L(M). Если её значение стало меньше, то разбиение M сохраняется и продолжается работа алгоритма. Иначе, если значение целевой функции L(M) не уменьшилось, то полученное разбиение M можно считать результатом выделения сообществ в сети.
Рассмотрим модификацию метода для неориентированных взвешенных сетей[3]. Введём относительный вес вершины α
![]() , (5)
, (5)
где: lα - множество инцидентных связей вершины α, wl - вес связи l. Тогда с учётом (5) задается относительный вес сообщества i
![]() .
.
Пусть ![]() - вес выхода из сообщества i
- вес выхода из сообщества i
![]() ,
,
где:![]() - множество связей, выходящих из сообщества i.
- множество связей, выходящих из сообщества i.
Общий вес связей, соединяющих сообщества
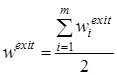 .
.
При использовании неориентированных взвешенных сетей метрика качества разбиения L(M) будет выглядеть следующим образом:
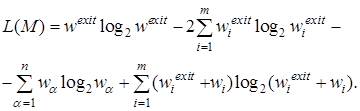 (6)
(6)
На основе рассмотренного численного алгоритма решения задачи выделения сообществ в социальных сетях для неориентированных взвешенных сетей разработан программный продукт на языке C# программной среды Microsoft Visual Studio.
Данные взяты из социальной сети ≪ВКонтакте≫ (vk.com) . Для примера будем рассматривать 345 случайных вершин. Вершины - это профили социальной сети, а связи - отношения дружбы между ними. На рисунке 1 слева расположены вершины сети, размещённые случайным образом, справа приведены размещения по результатам работы алгоритма.
Благодаря проведённым исследованиям эмпирических данных социальной сети ≪ВКонтакте≫ стало возможным составить следующий список свойств сообществ пользователей на уровне связей между пользователями в социальном графе:
· вершины в сообществе более тесно связаны друг с другом, чем с вершинами за пределами сообщества;
· сообщества могут пересекаться, т.е. один пользователь может относиться к нескольким сообществам, что хорошо согласуется с тем фактом, что человек одновременно может играть несколько социальных ролей в обществе;
· вершины с небольшой степенью чаще входят в небольшое число сообществ, тогда как вершины с большой степенью входят во множество сообществ.
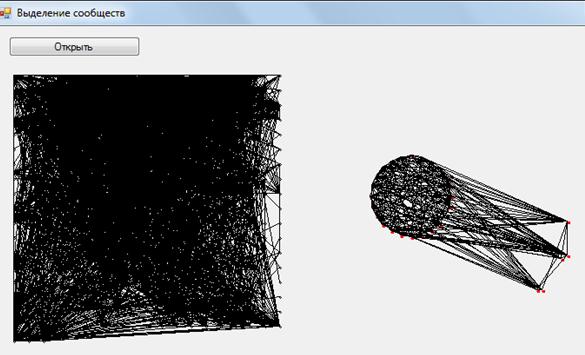
Рисунок 1. Выделение сообществ в социальных сетях. Количество вершин – 345
Результатом работы метода поиска сообществ является множество сообществ, в котором каждая вершина принадлежит как минимум одному сообществу.
В ходе исследования задачи кластеризации социальных сообществ на основе информационного содержания преобразован алгоритм выделения сообществ, который показывает возможность эффективного применения предложенной модификации к большим данным реальных социальных сетей.
Список литературы:
1. Батура Т.В. Методы анализа компьютерных социальных сетей // Вестн. НГУ, Сер. Информационныетехнологии. – 2012. – Т. 10, выпуск 4. – С. 13–28.
2. Girvan M., and Newman M.E. Community structure in social and biological networks//Proceedings of the National Academy of Sciences. – 2002. – 99 (12). – С. 7821–7826.
3. Коломейченко М.И., Чеповский А.А, Чеповский А.М. Алгоритм выделения сообществ в социальных сетях//Фундамент. иприкл. матем. – 2014. – Т. 19, выпуск 1. – С. 21–32.
4. Santo Fortunato. Community detection in graphs//Physics Reports. – 2010. – 486 (3). – С.75–174.
5. Clauset A., Newman M. E., Moore C. Finding community structure in very large networks // Phys. Rev. – 2004. – Vol. E 70, № 6.
6. Vincent D Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. Fast unfolding of communities in large networks // Journal of Statistical Mechanics: Theory and Experiment, 2008(10):P10008, 2008.
7. Lancichinetti A., Fortunato S., Radicchi F. Benchmark graphs for testing community detection algorithms // Phys. Rev. – 2008. – Vol. E 78, №4.
8. Lovasz L. Random walks on graphs: a survey // Combinatorics, Paul Erd˝os is Eighty /D. Mikl´os, V. T. S´os, T. Sz˝onyi, eds. – (Bolyai Soc. Math. Stud.; Vol. 2). – Budapest,1996. – P. 1–46.
9. Massen C.P., Doye J.P. K. Identifying communities within energy landscapes // Phys. Rev. – 2005. – Vol. E 71.
10. Newman M.E. Fast algorithm for detecting community structure in networks // Phys.Rev. – 2004. – Vol. E 69.
