Статья:




ОБНАРУЖЕНИЕ АНОМАЛИЙ В СЕТЕВОМ ТРАФИКЕ С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ
Конференция: CCLXXX Студенческая международная научно-практическая конференция «Молодежный научный форум»
Секция: Технические науки
Выходные данные
Доценко П.Е. ОБНАРУЖЕНИЕ АНОМАЛИЙ В СЕТЕВОМ ТРАФИКЕ С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ // Молодежный научный форум: электр. сб. ст. по мат. CCLXXX междунар. студ. науч.-практ. конф. № 1(280). URL: https://nauchforum.ru/archive/MNF_interdisciplinarity/1(280).pdf (дата обращения: 13.01.2025)
Голосование состоится 15.01.2025
Эта статья набрала 0 голосов
Мне нравится0
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
Дипломы
лауреатов
лауреатов
Сертификаты
участников
участников
CCLXXX Студенческая международная научно-практическая конференция «Молодежный научный форум»
ОБНАРУЖЕНИЕ АНОМАЛИЙ В СЕТЕВОМ ТРАФИКЕ С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМОВ МАШИННОГО ОБУЧЕНИЯ
Доценко Полина Евгеньевна
студент, Белгородский государственный национальный исследовательский университет, РФ, г. Белгород
Рост объема сетевого трафика и усложнение телекоммуникационных систем обусловливают необходимость разработки эффективных методов обнаружения аномалий. Традиционные подходы, такие как анализ пороговых значений, статистические методы и сигнатурный анализ, обладают рядом ограничений, связанных с их неспособностью адаптироваться к динамичным условиям современных сетей и изменяющимся угрозам. Анализ пороговых значений предполагает установление фиксированных границ параметров трафика и классификацию аномалий по следующей формуле:
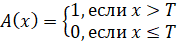 ,
,
где A(x) — наличие аномалии, x — значение метрики, T — пороговое значение.
Данный подход отличается простотой реализации, однако его эффективность ограничивается в условиях изменчивого трафика, характерного для современных телекоммуникационных систем. В таких условиях статические пороги могут быть либо слишком низкими, что приводит к множеству ложных срабатываний, либо слишком высокими, что делает систему нечувствительной к реальным угрозам.
Статистические методы, такие как z-score, предоставляют возможность выявления отклонений от среднего значения выборки. Расчет данного показателя производится по формуле:
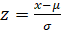 ,
,
где x — наблюдаемое значение, 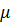 — среднее значение выборки,
— среднее значение выборки, 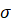 — стандартное отклонение.
— стандартное отклонение.
Эти методы позволяют учитывать статистические закономерности, но предполагают, что данные имеют нормальное распределение. На практике трафик в телекоммуникационных сетях часто характеризуется несимметричными и многомодальными распределениями, что ограничивает применимость данных методов. Кроме того, статистические подходы чувствительны к шумам в данных, которые могут существенно искажать результаты анализа.
Сигнатурный анализ, широко используемый в системах обнаружения вторжений (IDS), таких как Snort и Suricata, основан на сопоставлении поступающих данных с шаблонами известных угроз. Этот метод обеспечивает высокую точность при обнаружении атак, которые уже известны и зафиксированы в базе сигнатур. Однако он полностью неэффективен для выявления новых, ранее неизвестных угроз. Более того, обновление базы сигнатур требует значительных усилий, что ограничивает оперативность данного подхода в условиях постоянно меняющейся угрозы.
Современные подходы на основе машинного обучения обеспечивают значительное улучшение в области обнаружения аномалий за счет способности адаптироваться к изменениям структуры данных [1].
Контролируемые методы обучения, такие как логистическая регрессия, предполагают использование размеченных данных для создания моделей, которые способны классифицировать события как нормальные или аномальные [2]. Вероятность принадлежности события к классу аномалий рассчитывается по следующей формуле:
 ,
,
где w — вектор параметров, x — входные данные, b — смещение.
Такие методы демонстрируют высокую точность, особенно при наличии качественных размеченных данных. Однако они сталкиваются с проблемой дисбаланса классов, характерного для задач обнаружения аномалий, где число аномальных событий значительно меньше нормальных. Для компенсации этого дисбаланса применяются методы взвешивания классов или техники, такие как oversampling или undersampling.
Ненаблюдаемые методы, такие как Isolation Forest, предоставляют эффективное решение для анализа данных без предварительной разметки. Isolation Forest строит множество случайных деревьев, где каждый узел разделяет данные на основе случайно выбранного признака и значения. Аномалии идентифицируются как объекты, которые изолируются за меньшее количество шагов. Этот алгоритм оценивает степень изоляции точки x следующим образом:
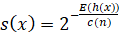 ,
,
где E(h(x)) — средняя длина пути до изолирования точки, c(n) — нормировочный коэффициент, зависящий от размера выборки n.
Isolation Forest эффективно работает с высокоразмерными данными и способен выявлять аномалии в многомерных распределениях. Качество его работы зависит от выбора гиперпараметров, таких как количество деревьев и их глубина, что требует дополнительной настройки.
Методы глубокого обучения, включая автоэнкодеры и рекуррентные нейронные сети (RNN), предоставляют дополнительные возможности для анализа сложных временных зависимостей [3]. Например, автоэнкодеры являются одним из наиболее популярных подходов. Это нейронные сети, состоящие из двух частей: энкодера, который уменьшает размерность входных данных, и декодера, который восстанавливает их. Функция потерь для автоэнкодера определяется как:
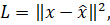
где x — входные данные, 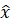 — восстановленные данные.
— восстановленные данные.
Высокое значение ошибки реконструкции сигнализирует о том, что объект сильно отличается от обучающих данных, что может указывать на аномалию. Рекуррентные нейронные сети (RNN), включая их модификации, такие как LSTM, применяются для анализа временных рядов. Они используют внутренние состояния для учета долгосрочных зависимостей в данных.
Гибридные подходы, объединяющие сигнатурный анализ и машинное обучение, обеспечивают высокую точность и адаптивность. Например, сигнатурный анализ используется для фильтрации известных шаблонов угроз, а ненаблюдаемые или глубокие методы применяются для обнаружения ранее неизвестных аномалий. В условиях современных сетей, таких как 5G, такие подходы становятся особенно актуальными из-за их способности масштабироваться и работать с разнообразными сценариями. Гибридные системы часто включают этапы предварительной обработки данных, что снижает нагрузку на вычислительные ресурсы и повышает общую производительность.
Таким образом, современные методы обнаружения аномалий демонстрируют значительное превосходство над традиционными подходами, обеспечивая высокую адаптивность, масштабируемость и точность. Однако их успешное применение требует не только качественных данных, но и тщательной настройки алгоритмов, учета специфики инфраструктуры и обеспечения достаточных вычислительных мощностей для обработки больших объемов трафика в реальном времени.
Список литературы:
1. Гудфеллоу И., Бенджио Й., Курвил А. Глубокое обучение. – М.: Издательство «ДМК Пресс», 2018. – 652 с.
2. Федоров А.В. Применение алгоритмов машинного обучения для анализа сетевого трафика // Вестник современных информационных технологий. – 2021. – №4. – С. 23–31.
3. Хайкин С. Нейронные сети: полный курс. – М.: Вильямс, 2006. – 1104 с.
