Автоматизированные способы получения новостной информации
Журнал: Научный журнал «Студенческий форум» выпуск №13(34)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №13(34)
Автоматизированные способы получения новостной информации
Для последующей обработки информации её требуется первоначально получить и привести в некоторый исходный для обработки вид.
Есть несколько различных вариантов для получения новостной информации из Интернета. Самый очевидный способ – прямое взаимодействие с html-страницей интернет ресурсов, на которых размещаются новости.
Для извлечения полезных данных из такого документа необходимо разработать систему, способную анализировать и обрабатывать неоднородную структуру html файлов.
В отличие от приведённого к стандартному виду формата расположения тэгов в документах типа XML, которые будут описаны далее, тэги в документах html хоть и имеют определённый порядок расположения своих основных элементов, в итоге в каждом случае представляют собой индивидуальный пример форматирования и применения различных функций.
Поскольку язык разметки гипертекста HTML представляет собой не столько средство для передачи структурированной информации, сколько средство для отображения содержимого веб-страниц, то и задача получения прямого доступа к информационным полям будет представлять из себя индивидуальную последовательность логических операций для каждого конкретного веб-сайта.
Рассмотрим структуру html-документа на примере строения страницы с новостями по теме «В мире» издания «Интерфакс» (рисунок 1).
Любой html документ состоит из двух больших частей: head и body. Они представляют собой два раздела, характеризуемых открывающим и закрывающим тегом, внутри которых располагается информация различного рода. В разделе, открываемом тегом head обычно располагается информация и функции, связанные с непосредственными характеристиками данной страницы, например, заголовок окна браузера или техническая информация для поисковых систем.
Тег body представляет собой основную часть документа, в котором прописаны все функции и ресурсы для построения отображения веб-страницы, в том числе и скриптовые команды на языке JavaScript. Обычно он занимает подавляющую часть html документа. В документе, по которому строится страница с новостями тематики «В мире» издания «Интерфакс», тег head занимает 23 строки html-кода, а тег body - 1224.
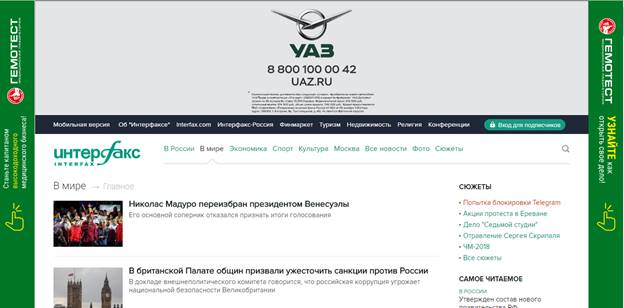
Рисунок 1. страница «В мире» издания «Интерфакс»
Реализовать данный алгоритм возможно с применением регулярных выражений – формальный язык поиска и осуществления манипуляций с подстроками в тексте.
Такую возможность предоставляет, например, среда Microsoft .NET в классе System.Text.RegularExpressions.Regex.
Механизм работы регулярных выражений позволяет выделять в тексте интересующие элементы, но он трудно адаптируем для обработки html-документов из-за вариативности их структуры внутри тега body. Особенно это проявляет себя при работе с такими массивными объемами документов у крупных сайтов вроде «Интерфакса».
В общем виде алгоритм обработки html-документа представлен на рисунке 2.
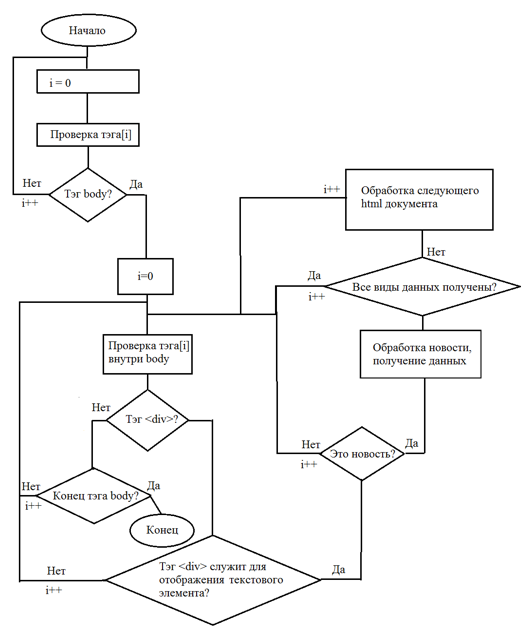
Рисунок 2. Пример алгоритма получения данных из html-документа
Однако у разработки такого решения есть ряд проблем – начиная от высокой трудоёмкости создания, заканчивая высоким потреблением ресурсов по причине неприспособленности регулярных выражений к работе с синтаксисом html, что означает большое количество дополнительного кода.
Также стоит отметить, что для каждого источника новостей придется делать свой отдельный алгоритм ввиду различий в структуре строения html-документов у различных веб-сайтов.
Помимо трудоёмкого «разбора» html-файлов с помощью регулярных выражений можно воспользоваться RSS-лентами изданий.
RSS (RichSiteSummary) – файл формата XML, предназначенный для краткого описания характера и содержания контента на веб-ресурсе.
Особенностью данного формата можно отметить встраиваемость. Вполне распространённой является практика, когда пользователь в одну ленту получает контент из нескольких RSS-лент. Для таких целей существует особый вид приложений – RSS-агрегатор. Подобное решение реализует потребность пользователя в оперативном информировании об интересующих его информационных поводах в рамках, заданных ресурсом, на чью ленту он подписан.
Существует несколько форматов RSS. Одним из них является формат RSS 2.0 – улучшенная версия форматов RSS 0.92 и 1.0. Также в 2005 появился формат Atom, позволяющий более гибко работать с представлением данных в коллекциях, в дальнейшем управляемыми стандартными методами HTTP.
Большинство крупных новостных ресурсов имеют свои RSS-ленты, представленные в RSS-канале.
Данные в RSS структурированы и информативны. Они разделены по тегам и обычно в наличии есть как заголовок новости, так и её описание, дата публикации и ссылка на оригинал.
Однако не все издания имеют свои RSS-каналы, а также зачастую не все они являются настолько же информативными и обновляемыми, как основной сайт, поэтому для получения актуальной новостной информации имеет смысл пользоваться сочетанием из обоих методов.
Также имеет смысл рассмотреть вариант работы с API новостных сервисов. API (application programming interface) – это набор готовых функций, методов, процедур и прочего, предоставляемых приложением, операционной системой или сервисом для облегчения работы сторонних продуктов.
API являются ключевыми структурами как при реализации приложений на различных платформах, включая различные устройства и операционные системы, так и при интегрировании функций сервисов друг в друга.
В основе взаимодействия с API лежит принцип «чёрного ящика» - необязательно знать, как работает та или иная функция, достаточно соблюдать соглашения, предоставлять методам данные согласно оговоренным параметрам, и правильно обрабатывать полученные результаты.
Зачастую различные веб-сервисы (в том числе веб-сайты), предоставляющие какие-либо данные посредством взаимодействия с API, реализуют передачу данных в специализированном, удобном для получения и хранения данных формате, например, JSON.
JSON (Java Script Object Notation) – текстовый формат для передачи данных. Несмотря на то, что в названии явно фигурирует JavaScript, формат является независимым и может использоваться почти со всеми языками программирования.
В российском сегменте Интернета стоит выделить сервис Google News как доступный способ получить новостные данные через API.
В заключении стоит отметить, что все три рассмотренных в статье варианта реализуемы и работоспособны, и при выборе какого-либо из них или сочетании друг с другом имеет смысл исходить как из необходимостей поставленной задачи, так и из технических средств и ресурсов (в том числе временных).
