ПРИМЕНЕНИЕ МЕТОДОВ СЭМПЛИРОВАНИЯ ДЛЯ УЛУЧШЕНИЯ КЛАССИФИКАЦИИ В ЗАДАЧЕ С ДИСБАЛАНСОМ КЛАССОВ
Журнал: Научный журнал «Студенческий форум» выпуск №42(309)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №42(309)
ПРИМЕНЕНИЕ МЕТОДОВ СЭМПЛИРОВАНИЯ ДЛЯ УЛУЧШЕНИЯ КЛАССИФИКАЦИИ В ЗАДАЧЕ С ДИСБАЛАНСОМ КЛАССОВ
Аннотация. В данной статье рассматривается проблема дисбаланса классов в задачах машинного обучения на примере классификации медицинских данных для диагностики диабета. Исследованы три алгоритма классификации: KNN (K-ближайших соседей), logistic regression (логистическая регрессия) и random Forest (случайный лес). Чтобы устранить дисбаланс классов применялись методы балансировки данных, включая Random Undersampling, random oversampling и SMOTE. Оценка эффективности проводилась с использованием метрик accuracy, precision, recall, F1-Score и ROC-AUC.
Ключевые слова: дисбаланс классов, машинное обучение, медицинские данные, диагностика диабета, KNN, логистическая регрессия, случайный лес.
- Данные и методология
2.1. Описание данных
Для исследования использовался набор данных diabetes_prediction_dataset (источник: Kaggle).
Исходный набор данных содержит 96146 записей, из которых 85.5% относятся к классу “здоровые” и 14.5% — к классу “диабет”. Этот диаграмма представлена на рис. 1.
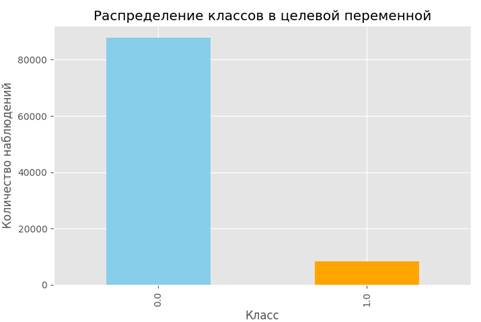
Рисунок 1. Распределение классов в целевой переменной
2.1. Методы классификации
Для решения задачи классификации применялись следующие алгоритмы:
K-ближайших соседей (KNN): «Этот метод работает с помощью поиска кратчайшей дистанции между тестируемым объектом и ближайшими к нему классифицированным объектами из обучающего набора.» [1].
Логистическая регрессия: «Логистическая регрессия выводит прогнозы о точках в бинарном масштабе — нулевом или единичном. Если значение чего-либо равно либо больше 0.5, то объект классифицируется в большую сторону (к единице). Если значение меньше 0.5 — в меньшую (к нулю)» [2].
Случайный лес (Random Forest): ансамблевый метод, использующий множество решающих деревьев. Алгоритм снижает риск переобучения и обеспечивает высокую устойчивость за счет случайной выборки признаков и данных на каждом этапе построения деревьев.
2.3. Методы балансировки данных
Для работы с дисбалансом классов в исследовании использовались следующие методы:
Random Undersampling: метод уменьшения выборки путем случайного удаления объектов из доминирующего класса.
Random Oversampling: метод увеличения выборки путем случайного дублирования объектов меньшего класса.
SMOTE (Synthetic Minority Oversampling Technique): метод генерации синтетических объектов для меньшего класса.
2.4. Метрики оценки
Для оценки качества классификации использовались следующие метрики:
Accuracy: доля правильно классифицированных объектов относительно общего числа объектов.
Precision: точность классификации положительного класса, отражающая долю истинных положительных результатов среди всех объектов, предсказанных как положительные.
Recall: полнота классификации положительного класса, показывающая долю правильно предсказанных положительных объектов относительно общего числа положительных объектов.
F1-Score: гармоническое среднее Precision и Recall, которое используется для учета баланса между этими метриками.
ROC-AUC: площадь под кривой ROC (Receiver Operating Characteristic), отражающая способность модели разделять классы;
- Результаты
3.1. Классификация до балансировки данных
Результаты работы алгоритмов без применения методов балансировки представлены в таблице 1:
Таблица 1.
Результаты классификации без применения методов балансировки
|
Алгоритм |
Accuracy |
Precision |
Recall |
F1-Score |
ROC-AUC |
|
KNN |
0.96 |
0.94 |
0.57 |
0.71 |
0.95 |
|
Logistic Regression |
0.89 |
0.43 |
0.89 |
0.58 |
0.96 |
|
Random Forest |
0.97 |
0.94 |
0.69 |
0.79 |
0.97 |
Результаты работы алгоритмов без применения методов балансировки демонстрируют высокие значения метрики Accuracy для всех моделей (от 0.89 до 0.97).
Показатель F1-Score, балансирующий Precision и Recall, оказался наилучшим у Random Forest (0.79), что делает его наиболее сбалансированным вариантом до применения методов балансировки.
Высокие значения ROC-AUC для всех моделей (более 0.95) демонстрируют хорошую способность разделять классы.
Тем не менее, такие результаты все равно указывают на значительные ограничения алгоритмов в условиях дисбаланса данных.
3.2. Классификация после балансировки данных
Результаты работы алгоритмов для метода Random Oversampling представлены в таблице 2:
Таблица 2.
Результаты классификации методом Random Oversampling
|
Алгоритм |
Accuracy |
Precision |
Recall |
F1-Score |
ROC-AUC |
|
KNN |
0.95 |
0.90 |
1.00 |
0.95 |
1.00 |
|
Logistic Regression |
0.88 |
0.89 |
0.88 |
0.88 |
0.96 |
|
Random Forest |
0.99 |
0.98 |
1.00 |
0.99 |
1.00 |
Результаты работы алгоритмов для метода Random Undersampling представлены в таблице 3:
Таблица 3.
Результаты классификации методом Random Undersampling
|
Алгоритм |
Accuracy |
Precision |
Recall |
F1-Score |
ROC-AUC |
|
KNN |
0.89 |
0.87 |
0.91 |
0.89 |
0.96 |
|
Logistic Regression |
0.88 |
0.89 |
0.88 |
0.88 |
0.96 |
|
Random Forest |
0.90 |
0.90 |
0.90 |
0.90 |
0.97 |
Результаты работы алгоритмов для метода Random Undersampling представлены в таблице 4:
Таблица 4.
Результаты классификации методом SMOTE
|
Алгоритм |
Accuracy |
Precision |
Recall |
F1-Score |
ROC-AUC |
|
KNN |
0.94 |
0.91 |
0.99 |
0.94 |
0.99 |
|
Logistic Regression |
0.89 |
0.89 |
0.88 |
0.89 |
0.96 |
|
Random Forest |
0.98 |
0.97 |
0.98 |
0.98 |
1.00 |
Применение методов балансировки данных значительно улучшило качество работы моделей машинного обучения, особенно в идентификации меньшего класса. Результаты работы алгоритмов с разными подходами представлены ниже.
Метод Random Oversampling продемонстрировал значительное улучшение Recall для всех моделей. KNN и Random Forest достигли Reыыcall = 1.00, что означает полное распознавание объектов меньшего класса.
Метод Random Undersampling, напротив, снизил значения Accuracy, так как уменьшение выборки большего класса сокращает общий объем данных.
Метод SMOTE обеспечил наиболее сбалансированные результаты, генерируя синтетические данные для меньшего класса. KNN и Random Forest снова показали высокие значения Recall, сохранив при этом высокие показатели Precision.
Заключение
В ходе исследования продемонстрировано, что применение методов балансировки данных оказывает значительное влияние на качество классификации в задачах с дисбалансом классов. Методы Random Oversampling, Random Undersampling и SMOTE эффективно справляются с данной проблемой, однако наилучшие результаты были достигнуты при использовании метода SMOTE в сочетании с алгоритмом Random Forest.
Результаты подтверждают, что использование методов балансировки данных, таких как SMOTE, и мощных алгоритмов классификации, таких как Random Forest, рекомендуется при разработке систем поддержки принятия решений в медицине. Эти подходы могут также успешно применяться в других областях, где проблема дисбаланса классов влияет на точность и надежность прогнозов.
