RECOMMENDATION SYSTEM METHODS FOR ONLINE SUPERMARKETS USING AI
Журнал: Научный журнал «Студенческий форум» выпуск №21(244)
Рубрика: Технические науки

Научный журнал «Студенческий форум» выпуск №21(244)
RECOMMENDATION SYSTEM METHODS FOR ONLINE SUPERMARKETS USING AI
МЕТОДЫ РЕКОМЕНДАТЕЛЬНОЙ СИСТЕМЫ ДЛЯ ОНЛАЙН СУПЕРМАРКЕТОВ ИСПОЛЬЗУЯ ИИ
Сункарбеков Елдар Серикбекулы
магистрант, Международный Университет Информационных Технологий, РК, г. Алматы
Аннотация. Ценная информация может быть использована продуктовыми ритейлерами для улучшения своих маркетинговых стратегий и операционной деятельности. В этой статье автор предлагает изучить алгоритмы машинного обучения для разработки персонализированной системы рекомендаций по спискам покупок. Предлагаемая система предназначена для рассмотрения различных типов алгоритмов, которые могут быть интегрированы с различными интернет-супермаркетами.
Abstract. Valuable information can be used by grocery retailers to improve their marketing strategies and operational activities. In this article, the author suggests studying machine learning algorithms to develop a personalized system of recommendations for shopping lists. The proposed system is designed to consider various types of algorithms that can be integrated with various online supermarkets.
Ключевые слова: Искусственный интеллект, матрица факторизации, рекомендательная система, машинное обучение.
Keywords: Artificial Intelligence, factorization matrix, recommendation system, machine learning.
Recommendation systems powered by artificial intelligence (AI) have emerged as a solution to this problem. Recommendation systems use machine learning algorithms to analyze customer data, such as purchase history and search queries, to provide personalized recommendations for products that the customer may be interested in. In the context of online supermarkets, these systems can increase customer satisfaction by helping them find the products they need more efficiently, while also increasing sales for the supermarket.
The recommender system is designed to be expandable and customizable, allowing the possibility of training the model with data from different retailers. Both the quality of predictions and the performance of the solution are crucial factors in achieving the desired outcome, and thus, they are thoroughly measured and analyzed. To evaluate the quality of the recommender system, two non-machine learning approaches provided by the organization are utilized for comparison. Additionally, the performance is evaluated under a simulated workload to assess its efficiency [1].
Recommendation systems can be evaluated using metrics such as accuracy, coverage, and diversity. Accuracy measures how well the system predicts the preferences of the user, while coverage measures how many items in the catalog the system can recommend. Diversity measures how much variety there is in the recommended items. These metrics can help developers optimize the performance of the recommendation system and improve the customer experience.
Reliability in the context of a system refers to its behavior and encompasses aspects such as availability, precision, and failure recovery. In the scope of this project, specific reliability requirements have been identified, which are outlined below:
1.The system should maintain its availability even after experiencing an error in a previous operation. This means that if an error occurs, the system should handle it appropriately and continue functioning without causing a complete system failure or disruption.
2.The system should effectively handle errors that may occur within internal operations or requests, ensuring that these errors are contained and do not propagate to other components or adversely affect the overall system functionality. It is essential to implement mechanisms and strategies to isolate and manage errors internally, minimizing their impact on the system's stability and performance.
By adhering to these reliability requirements, the recommender system can maintain its availability, continue providing accurate recommendations, and ensure that errors are contained within the affected components without causing system-wide failures. This contributes to a more robust and reliable system overall [2].
The sections below present some of the most typical classifications for recommender systems, according to the literature:
1.Content-Based Recommendations.
2.Collaborative Recommendations.
3.Demographic-Based Recommendations.
4.Interactive Recommendations.
5.Context-Based Recommendations.
Content-based recommender systems, also called cognitive filter recommender systems, are well-known for their simplicity. Collaborative recommender systems, also referred to as "social filter" or "collaborative filtering" recommender systems, make recommendations by analyzing users' behavior. Demographic-based recommender systems are hybrid approaches that use user-user relationships to generate predictions. Different solutions may collect this information in various ways, but they aim to gather data that enables the system to calculate user profiles.
However, generating knowledge from contextual information can be challenging, making this approach complex to implement, despite its promising results and academic interest. Picture 1 shows the most basic types of machine learning (ML).

Picture 1. Types of machine learning
The primary objective of AI is to simulate human-like intelligence in order to solve complex problems, while ML aims to learn from collected data to enhance the machine's performance for a specific task. Thus, ML can be seen as a system that learns new information from the data it gathers [3]. When it comes to decision-making, AI strives to obtain the most suitable solution, while ML focuses on finding a single answer, regardless of whether it is optimal or not. AI leads to the development of intelligence and wisdom, whereas ML leads to knowledge acquisition. It is worth noting that while AI works towards making decisions and arriving at optimal solutions, ML is limited to considering a single answer.
Matrix Factorization - it decomposes the utility matrix into two sub matrices. During prediction, we multiply the two sub-matrices to reconstruct the predicted utility matrix. The utility matrix is factorized such that the loss between the multiplication of these two and the true utility matrix is minimized. One commonly used loss function is mean-squared error. Example on Picture 2.
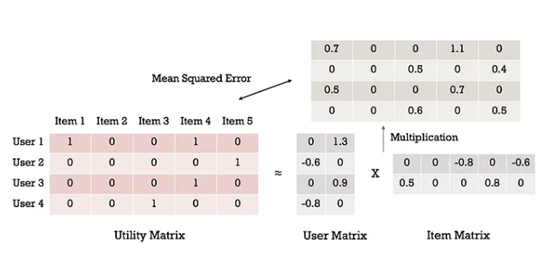
Picture 2. utility matrix
Matrix Factorization is a popular technique used in recommendation systems to model and predict user-item interactions. It aims to factorize a user-item interaction matrix into two lower-dimensional matrices: one representing user and the other representing items.
In summary, Matrix Factorization is a technique used in recommendation systems to decompose the user-item interaction matrix into lower-dimensional matrices and extract latent factors. It enables personalized recommendations by predicting missing entries in the matrix [4]. While it has advantages in handling sparsity and scalability, it may have limitations in capturing complex relationships and incorporating contextual information. Hybrid approaches can be used to overcome these limitations and enhance recommendation accuracy.
Accuracy is used as an evaluation metric in recommendation systems to assess the effectiveness and performance of the system's recommendations. It measures how accurately the recommendations align with the preferences or interests of the users.
In neural networks, accuracy is a measure of how well the model is able to correctly classify examples from the test dataset. It is calculated as the ratio of the number of correctly classified examples to the total number of examples in the test dataset. In other words, accuracy measures the percentage of correct predictions made by the model on the test dataset.
Let's check the results of our accuracy in the diagram on Picture 3.

Picture 2. Accuracy for 30 epochs
Based on this research, the author identified gradient boosted tree algorithms, neural networks, and SVMs as the most promising approaches for developing a machine learning model for grocery retail [5]. These techniques were found to deliver the best results and show greater consistency across different domains. The passage also notes that there are various technologies available for developing machine learning algorithms, and TensorFlow was chosen as the framework for this dissertation due to its popularity and strong community support. Additionally, TensorFlow provides support for both CPU and GPU, which leads to faster results when working with models.
Developing a recommender system for grocery retail is a challenging task due to the unique characteristics of the industry. In order to create an effective model, it was crucial to extract as much knowledge as possible from the dataset used in the case study. This knowledge was translated into features, which played a critical role in helping the gradient boosted trees model learn patterns that are specific to different customers, products, and their relationships.
